

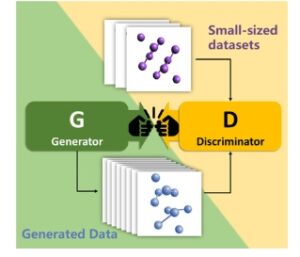
Abstrak Grafis
Metode yang efisien berdasarkan jaringan adversarial generatif diusulkan menggunakan kumpulan data berukuran kecil. Ruang konfigurasi kluster atom dan molekul diselidiki untuk menunjukkan kemampuan pembangkitan metode yang diusulkan. Hasil tolok ukur menunjukkan kinerja yang unggul dibandingkan algoritma genetika yang banyak digunakan. Penggabungan fungsi penjepit dinamis secara efektif mengurangi keruntuhan mode, memastikan keragaman dan keandalan.
Abstrak
Penelitian klaster memainkan peran penting dalam kimia. Untuk mengeksplorasi ruang konfigurasi klaster, biasanya diperlukan pencarian skala besar. Namun, untuk beberapa contoh, konfigurasi klaster yang diinginkan mungkin berlawanan dengan intuisi, sehingga sulit untuk memberikan tebakan awal yang wajar untuk mencari nilai minimum yang sesuai. Ada beberapa rute untuk menghasilkan konfigurasi klaster. Namun, rute tersebut mungkin mengalami masalah dimensi atau memerlukan prasyarat lain. Dalam karya ini, jaringan adversarial generatif (GAN) digunakan untuk menghasilkan konfigurasi klaster secara efisien berdasarkan kumpulan data berukuran kecil. Fungsi penjepit dinamis diperkenalkan selama pelatihan. Ukuran kumpulan data dikontrol agar berada pada urutan besaran puluhan hingga ratusan sampel. Lebih jauh, volume dan area convex hull ditetapkan untuk membantu mengidentifikasi struktur yang unik. Ditemukan bahwa arsitektur GAN yang diusulkan tidak sensitif terhadap struktur jaringan dan dapat digunakan secara efektif untuk menghasilkan konfigurasi klaster baru. Fungsi penjepit dinamis yang diperkenalkan secara signifikan mengurangi masalah mode collapse. Dibandingkan dengan penelitian sebelumnya, ukuran kumpulan data jauh berkurang untuk menghindari pelatihan skala besar. Kumpulan data yang berisi kurang dari 200 sampel sudah memberikan hasil yang memuaskan. Metode ini berkinerja lebih baik daripada algoritma genetika dan diharapkan memiliki berbagai skenario aplikasi kimia.
1 Pendahuluan
Penelitian klaster merupakan bidang menarik yang mengeksplorasi sifat dan perilaku unik dari kumpulan atom atau molekul. Klaster berfungsi sebagai bagian dari jembatan antara dunia mikroskopis atom dan molekul individual dan dunia makroskopis material massal. Studi klaster tidak hanya dapat memberikan wawasan tentang hukum dasar yang mengatur materi pada skala nano, tetapi juga membuka kemungkinan baru untuk desain material baru dengan sifat yang disesuaikan untuk aplikasi mulai dari katalisis dan penyimpanan energi hingga optoelektronik dan biomedis. [ 1 – 3 ]
Penentuan konfigurasi klaster memainkan peran mendasar dalam ilmu klaster dalam hal mengungkap mekanisme pertumbuhan, mengidentifikasi karakteristik struktural, dan mengkorelasikan dengan sifat-sifat baru. [ 4 , 5 ] Namun, penentuan konfigurasi bukanlah tugas yang mudah. Untuk memfasilitasi pembuatan konfigurasi, berbagai pendekatan telah diusulkan. Salah satu caranya adalah dengan menggunakan algoritma genetika untuk menghasilkan konfigurasi klaster. [ 6 ] Namun, algoritma genetika bekerja kurang baik untuk skenario berdimensi tinggi. [ 7 ] Rute lain adalah dengan mengeksplorasi (semua) kemungkinan konfigurasi yang dibatasi oleh aturan yang berbeda, [ 8 – 11 ] seperti pustaka sudut torsi dan ketersediaan rotasi ikatan. Pendekatan ketiga bergantung pada dinamika molekuler atau simulasi Monte Carlo untuk menghasilkan konfigurasi. [ 12 ] Dalam kasus ini, medan gaya yang tepat harus dibangun. [ 13 – 15 ]
Dalam beberapa tahun terakhir, teknik pembelajaran mesin (ML) berdasarkan jaringan saraf telah diusulkan untuk menghasilkan struktur molekuler baru. Misalnya, dengan menggunakan jaringan adversarial generatif (GAN), Huang dan rekan kerja berupaya memprediksi struktur protein, tetapi struktur yang tidak realistis dapat dihasilkan. [ 16 ] Variational autoencoder (VAE) kemudian diterapkan untuk desain tulang punggung protein. [ 17 ] Model generatif, seperti GAN, sangat menarik dalam hal menghasilkan data baru dengan mempelajari distribusi data. Perbedaan utama GAN dari teknik ML lainnya adalah bahwa GAN terdiri dari dua jaringan dan kedua jaringan bersaing satu sama lain hingga mencapai keseimbangan Nash. [ 18 – 20 ]
Ada sejumlah studi terbatas yang menggunakan GAN untuk menghasilkan struktur baru. Menggunakan GAN kondisional, Gebauer dan rekan kerja melatih 55.000 struktur referensi menggunakan fitur 128 dimensi per atom dan 9 blok interaksi untuk menghasilkan struktur molekuler 3D dengan sifat yang diinginkan. [ 21 ] Menggabungkan GAN dengan pembelajaran penguatan, Kim dan rekan kerja melatih jutaan string SMILES untuk menghasilkan struktur molekuler. [ 22 ] De Cao dan rekan kerja menganggap molekul sebagai grafik tak berarah dan menggunakan Wasserstein GAN untuk melatih miliaran molekul. [ 23 ] Huang dan rekan kerja memanfaatkan GAN konvolusional dalam untuk melatih dataset Protein Data Bank menggunakan jarak berpasangan sebagai fitur input. [ 16 ] Maziarka dan rekan kerja menggunakan cycle-GAN untuk menghasilkan molekul dengan struktur serupa dengan struktur optimal. Metode ini melatih ratusan ribu molekul dan mengkategorikan molekul basis data dengan sifat spesifik menjadi fitur input dan output. [ 24 ] Chen dan rekan kerjanya menggabungkan Wasserstein GAN dengan teknik ML lainnya untuk melatih jutaan SMILES untuk desain molekul. [ 25 ] Di luar pembuatan molekul, kerangka kerja GAN telah diaplikasikan ke berbagai macam tugas, termasuk pembuatan peptida atau protein, [ 26 – 29 ] urutan DNA atau RNA, [ 30 – 32 ] molekul obat atau molekul terfungsionalisasi lainnya, [ 33 – 36 ] struktur keadaan transisi, [ 37 ] reaksi baru, [ 38 ] material baru, [ 39 ] dinamika stokastik, [ 40 ] dan energi untuk geometri molekul tertentu. [ 41 ] GAN juga telah digunakan untuk pengenalan gambar sel kanker, [ 42 ] pengembangan sensor lunak, [ 43 ] denoising spektrum inframerah 2D ultracepat, [ 44 ] dan analisis gambar difraksi elektron ultracepat. [ 45 ]
Meskipun berhasil, dapat dilihat bahwa penelitian sebelumnya sebagian besar dilatih pada basis data yang sangat besar. Akan menarik untuk meneliti apakah kumpulan data berukuran kecil dapat digunakan untuk memprediksi konfigurasi klaster, dan seperti apa kinerjanya. Selain itu, model sebelumnya terutama berfokus pada molekul organik, sedangkan klaster memiliki kompleksitas struktural ekstra. Lebih jauh, beberapa di antaranya mengalami masalah keruntuhan mode atau menghasilkan molekul yang tidak realistis. Terakhir, pembuatan struktur baru oleh GAN memiliki tantangan tambahan dibandingkan dengan skenario pembuatan gambar yang dipelajari secara luas, dan penerapan GAN pada pembuatan konfigurasi klaster masih belum dieksplorasi. Dalam karya ini, kami mengusulkan metode yang efisien berdasarkan kerangka kerja GAN dan menggabungkan fitur dari teknik ML lainnya. Model dilatih pada kumpulan data yang hanya terdiri dari puluhan hingga ratusan konfigurasi. Klip dinamis diperkenalkan selama pelatihan yang secara signifikan mengurangi masalah keruntuhan mode. Koordinat yang diratakan diadopsi sebagai fitur input dan output. Ini memfasilitasi pelatihan dan menghindari konversi SMILES atau grafik molekuler, yang dapat menyebabkan hilangnya informasi karena transformasi 3D-2D. Fungsi layar diterapkan pada model yang telah dilatih untuk pasca-perlakuan. Perhitungan tolok ukur menunjukkan bahwa model yang diusulkan dapat secara efektif menghasilkan konfigurasi klaster baru dengan tingkat keberhasilan yang memuaskan. Organisasi naskah diplot pada Gambar S1, Informasi Pendukung.
2 Metode dan Rincian Perhitungan
Klaster yang dijadikan acuan dalam penelitian ini meliputi Al 12 , P 11 , Mg 10 , Na 10 , dan klaster biner Al 4 Si 7 . Struktur diambil langsung dari konfigurasi yang telah dioptimalkan sebelumnya. [ 46 ] Ukuran dataset untuk setiap klaster masing-masing adalah 43, 184, 16, 13, dan 74, yang jauh lebih kecil dibandingkan penelitian sebelumnya.
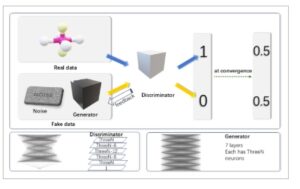
Arsitektur GAN terdiri dari dua jaringan: jaringan generator (G) dan jaringan diskriminator (D). Gambar 1 menyajikan arsitektur GAN dan struktur dasar jaringan generator dan diskriminator.
Gambar 1
Buka di penampil gambar
Arsitektur GAN dan struktur dasar jaringan komponen yang diusulkan dalam karya ini. Diskriminator dan generator adalah jaringan saraf yang terhubung penuh yang bersaing satu sama lain secara berulang hingga mencapai keseimbangan. Diskriminator membedakan data nyata dari data palsu yang dihasilkan, sementara generator mengoptimalkan dirinya sendiri untuk “menipu” diskriminator. Panel bawah menggambarkan struktur umum untuk kedua jaringan dalam hal jumlah lapisan dan jumlah neuron per lapisan. “ThreeN” menunjukkan ada 3×N neuron, di mana N adalah jumlah atom dalam molekul.
Tujuan optimasi secara keseluruhan adalah untuk menemukan distribusi dari jaringan generator, yang tidak akan dibedakan oleh jaringan diskriminator. Untuk jaringan generator, fungsi optimasinya, G ( z ), dapat disederhanakan sebagai
![]()
di mana z adalah vektor acak masukan, F menunjukkan fungsi aktivasi atau fungsi normalisasi, dan w dan b menunjukkan bobot dan bias untuk setiap lapisan dalam jaringan. Untuk kenyamanan, G ( z ) dilambangkan sebagai x G untuk penggunaan terakhir.
Demikian pula, fungsi optimasi jaringan diskriminator dapat disederhanakan sebagai
![]()
di mana x menyatakan vektor data riil atau x G dari generator.
Seperti yang dibahas, jaringan yang terhubung penuh digunakan dalam pekerjaan ini. Dimensi vektor z ditetapkan sebagai 3 N , di mana N adalah jumlah atom dalam klaster. Matriks w membentuk ulang vektor fitur ke dalam dimensi yang diinginkan dengan bobot yang tepat. Misalnya, matriks w dengan dimensi [3 N -6, 3 N ] akan membentuk ulang vektor input dari dimensi 3 N menjadi 3 N -6. Ini adalah representasi matematis untuk transformasi 1-lapisan dalam jaringan. Ketika beberapa lapisan disertakan, matriks w dan vektor b membentuk ulang diri mereka sendiri sesuai dengan hiperparameter. Misalnya, jaringan dengan 10 lapisan melakukan 10 transformasi berturut-turut, sementara jumlah neuron menentukan bentuk matriks w dan vektor b . Setelah pelatihan, generator akan menghasilkan vektor output menggunakan Persamaan ( 1 ), yang merepresentasikan geometri struktur baru.
Tujuan optimasi D adalah meminimalkan perbedaan antara D ( x riil ) dan nilai sebenarnya, sekaligus meminimalkan perbedaan antara D ( x G ) dan nilai salah.
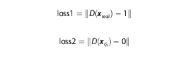
di mana kerugian didefinisikan sebagai norma L2.
Sebaliknya, tujuan optimasi G adalah memaksimalkan D ( x G ) sehingga D ( x G ) mendekati satu sebanyak mungkin. Oleh karena itu, jaringan G dan D bersaing satu sama lain hingga keseimbangan Nash tercapai.
![]()
Namun, penggunaan Persamaan ( 5 ) untuk melatih model akan menemui masalah keruntuhan mode, di mana keragaman konfigurasi yang dihasilkan berkurang. Untuk mengatasi masalah ini, kami memperkenalkan fungsi penjepit dinamis, yang membatasi parameter D ke ruang yang kompak. Secara khusus, nilai penjepit ditentukan secara dinamis selama proses pelatihan dari ±0,1 hingga ±0,01 pada panjang langkah 0,00125.
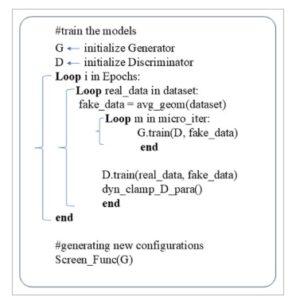
Dengan demikian, keseluruhan algoritma dijelaskan secara singkat pada Gambar 2. Kerugian mean squared error (MSE) untuk jaringan generator dan diskriminator memberikan umpan balik pada jaringan dan mengoptimalkan parameter secara berulang hingga mencapai keseimbangan.
Gambar 2
Buka di penampil gambar
Kode semu untuk prosedur pelatihan GAN. G dan D adalah jaringan yang diinisialisasi dengan benar dengan parameter (yaitu, bobot dalam matriks w yang didefinisikan dalam Persamaan ( 2 )) yang akan dioptimalkan. Epoch menentukan jumlah iterasi untuk pelatihan. Fungsi avg_geom digunakan untuk menghasilkan data palsu awal dengan merata-ratakan data basis data dengan noise yang tepat. Fungsi train melakukan pembaruan parameter standar untuk setiap jaringan. Fungsi dyn_clamp_D_para memperkenalkan fungsi clamp ke parameter discriminator. Terakhir, fungsi Screen_Func digunakan untuk postprocessing guna menyaring beberapa struktur yang dihasilkan secara tidak fisik.
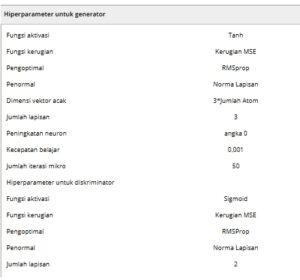
Hiperparameter yang relevan untuk jaringan dirangkum dalam Tabel 1. Untuk G dan D, fungsi aktivasi dan lapisan normalisasi disisipkan di antara setiap lapisan tersembunyi.
Tabel 1. Hiperparameter yang digunakan untuk pekerjaan ini.
Fungsi aktivasi memperkenalkan transformasi nonlinier antar lapisan. Dalam karya ini, kami memilih fungsi tangen hiperbolik (Tanh) untuk generator dan fungsi Sigmoid untuk diskriminator. Bentuk matematika untuk fungsi Tanh dan fungsi Sigmoid adalah
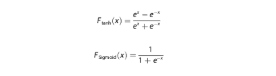
Rentang keluaran untuk fungsi Tanh dan Sigmoid masing-masing adalah (−1, 1) dan (0, 1).
Fungsi kerugian mengevaluasi kesalahan setiap jaringan, dan pengoptimal meminimalkan kedua fungsi kerugian secara berulang hingga mencapai konvergensi. Fungsi pengoptimal mengatur strategi pengoptimalan dan tingkat pembelajaran menunjukkan panjang langkah dalam bahasa masalah pengoptimalan umum. Iterasi mikro adalah loop yang ditentukan sendiri untuk membantu melatih generator. Jumlah lapisan dan penambahan neuron digunakan untuk menetapkan jumlah lapisan dan neuron, masing-masing.
Perlu disebutkan bahwa hasil pelatihan tidak sensitif terhadap struktur jaringan dalam hal jumlah lapisan atau neuron. Namun, ukuran parameter untuk kedua jaringan harus tetap sebanding; jika tidak, satu jaringan dapat mendominasi yang lain, sehingga mengganggu proses pelatihan yang saling bertentangan. Yang penting, fungsi klip dinamis diusulkan dalam karya ini, yang secara signifikan memengaruhi keragaman hasil pelatihan. Pembahasan terperinci akan diberikan di bagian selanjutnya.
Setelah melatih jaringan, konfigurasi klaster dihasilkan dengan menerapkan generator yang telah dilatih pada vektor masukan acak dengan distribusi Gaussian. Simpangan baku untuk distribusi Gaussian dipilih secara acak dari rentang antara 1,5 dan 2,0, yang merupakan rentang distribusi atom sampel riil dalam basis data yang diberikan. Fungsi layar diperkenalkan untuk menghilangkan konfigurasi yang dihasilkan yang panjang ikatannya terlalu pendek (<1,7 Å) atau terlalu panjang (>8 Å) dan distribusinya berada di luar rentang [1.2, 2.2].
Untuk memeriksa apakah konfigurasi yang dihasilkan sesuai dengan minimum sebenarnya, optimasi dilakukan dengan menggunakan fungsional TPSSH [ 47 ] dan basis set pcseg-1, [ 48 ] yang dipilih agar konsisten dengan studi basis data. [ 46 ] Analisis getaran dilakukan pada tingkat teori yang sama dan semua konfigurasi yang dihasilkan ditemukan sebagai minimum yang sebenarnya.
3 Hasil dan Pembahasan
3.1 Perilaku Konvergensi
Gambar 3 menunjukkan kurva konvergensi fungsi kerugian generator dan diskriminator selama proses pelatihan untuk klaster Al 12. Fungsi kerugian MSE didefinisikan sebagai
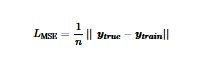
di mana y true dan y train masing-masing mewakili nilai true dan nilai prediksi. Prefaktor n merupakan konstanta normalisasi dan norma L2 diambil untuk menghitung nilai kerugian. Fungsi kerugian untuk generator dan diskriminator dihitung sebagai 0,58 dan 0, masing-masing setelah iterasi pertama. Selanjutnya, kedua nilai kerugian berfluktuasi sekitar 0,25.
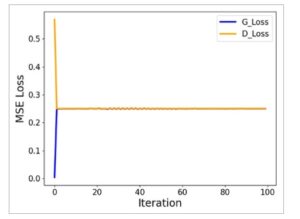
Gambar 3
Buka di penampil gambar
Kurva konvergensi fungsi kerugian generator dan diskriminator untuk klaster Al 12 .
Dapat dilihat bahwa kedua kurva kerugian akhirnya konvergen ke 0,25. Berdasarkan rancangannya, generator yang terlatih dengan baik harus menghasilkan sampel yang tidak dapat dibedakan dari sampel asli oleh diskriminator. Oleh karena itu, diskriminator mengevaluasi sampel yang dihasilkan sebagai 50% asli dan 50% palsu. Karena kerugian MSE digunakan untuk mengukur kerugian, konvergensi ke 0,25 menunjukkan terbentuknya ekuilibrium Nash (kuadrat 0,5 adalah 0,25).
3.2 Evaluasi Konfigurasi yang Dihasilkan dan Tingkat Hit
Gambar 4 menunjukkan struktur basis data Na 10 (dalam kotak biru) dan struktur terpilih yang dihasilkan (dalam kotak hijau). Dapat dilihat bahwa struktur basis data memiliki sedikit aturan atau pola yang dapat digunakan untuk merasionalisasi konfigurasinya. Akibatnya, akan sangat sulit untuk mengusulkan konfigurasi baru secara manual hanya dengan mengamati konfigurasi yang sudah ada. Dapat ditambahkan bahwa dua struktur basis data secara struktural serupa (konfigurasi kiri dan konfigurasi tengah pada baris terakhir kotak biru). Sementara untuk yang lain, strukturnya lebih berbeda, namun sulit untuk mengidentifikasi perbedaan tersebut dengan mata telanjang.

Gambar 4
Buka di penampil gambar
Struktur basis data representatif Na 10 (dalam kotak biru) dan struktur representatif yang dihasilkan Na 10 (dalam kotak hijau). Struktur representatif yang dihasilkan untuk kluster lain dapat ditemukan dalam informasi pendukung.
Oleh karena itu, penting untuk merancang metode guna menemukan hasil yang unik. Perbandingan koordinat molekuler tidaklah efektif, karena konfigurasi klaster yang sangat berbeda mungkin memiliki distribusi atom yang serupa. Misalnya, Gambar 5 b,c menunjukkan struktur dua konfigurasi untuk klaster Al 12 yang disertakan dalam basis data terkait. Dapat dilihat bahwa kedua konfigurasi tersebut sangat berbeda, namun nilai distribusi atomnya (std) cukup mirip (1,68 versus 1,67). Kriteria energi juga tidak selalu valid, karena kami menemukan bahwa untuk kasus tertentu, konfigurasi yang jelas berbeda mungkin memiliki nilai energi yang hampir sama.
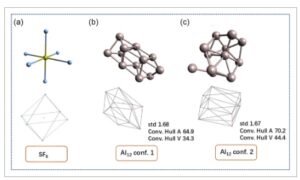
Gambar 5
Buka di penampil gambar
Kulit cembung untuk molekul terpilih. a) Kulit cembung molekul SF6 oktahedral ( oktahedron dengan 6 atom F titik puncak). b,c) Struktur dua konfigurasi untuk gugus Al12 dari basis data terkait.
Untuk memecahkan masalah ini, kami membangun convex hull untuk mengidentifikasi perbedaan antara konfigurasi. [ 49 , 50 ] Convex hull didefinisikan sebagai polihedron terkecil yang membungkus molekul. Misalnya, convex hull dari molekul oktahedral SF6 akan menjadi oktahedron yang terdiri dari 6 atom F verteks (Gambar 5a ). Dengan membangun convex hull, kita kemudian dapat menghitung luas permukaan dan volume convex hull tersebut, yang nilainya jauh lebih dapat dibedakan dibandingkan dengan nilai distribusi (Gambar 5b,c ). Secara keseluruhan, kami menggunakan properti convex bersama dengan kriteria energi untuk membedakan struktur klaster yang unik.
Setelah menjalankan pemilihan convex hull dan membandingkan energi, kami menghitung konfigurasi unik dengan pembangkitan GAN dan menghitung rasio keberhasilan. Rasio keberhasilan didefinisikan sebagai rasio antara struktur unik yang dihasilkan terhadap total struktur yang dihasilkan, yang dalam praktiknya adalah 100. Perlu ditambahkan bahwa 100 sampel yang dihasilkan semuanya adalah sampel unik sebelum pengoptimalan geometri. Jadi, ketika hanya mempertimbangkan pembangkitan sampel yang berbeda untuk tebakan awal, metode yang diusulkan dapat berhasil memenuhi tujuan, di mana struktur yang sulit diprediksi dapat dieksplorasi. Seseorang mungkin berpendapat bahwa pencarian acak dengan kekuatan kasar sederhana mungkin juga berhasil. Namun mengingat kendala yang digunakan dalam pekerjaan ini, seperti panjang ikatan dan distribusi, seharusnya masuk akal, pendekatan kekuatan kasar acak tidak dapat menghasilkan 100 struktur setelah 12 jam, sedangkan dibutuhkan beberapa menit dengan metode yang diusulkan menggunakan komputer desktop biasa.
Dalam praktiknya, ketika menjalankan optimasi, beberapa struktur yang dihasilkan akan dioptimalkan ke minimum lokal yang sama. Dengan demikian, kami menghitung rasio hit untuk mengukur konfigurasi unik. Tabel 2 menunjukkan rasio hit klaster yang dijadikan tolok ukur dalam studi ini. Sebagai perbandingan, rasio hit yang dihitung oleh algoritma genetika juga tercantum dalam Tabel 2. Dapat dilihat bahwa rasio hit umumnya berskala dengan ukuran kumpulan data. Khususnya, metode yang diusulkan dapat digunakan bahkan dengan kumpulan data yang sangat kecil, meskipun rasio hitnya relatif rendah. Sebagai perbandingan, metode genetika bahkan tidak dapat menghasilkan sejumlah konfigurasi yang signifikan secara statistik. Ketika meningkatkan ukuran kumpulan data, rasio hit untuk kedua metode meningkat, dan metode yang diusulkan sedikit lebih baik daripada metode genetika. Untuk ukuran kumpulan data 185, rasio hit mencapai 79%, yang memuaskan mengingat ukuran data yang terbatas.
Tabel 2. Tingkat keberhasilan konfigurasi yang dihasilkan untuk setiap klaster.

a) Setelah optimasi;
b) Tidak dapat menghasilkan jumlah konfigurasi yang signifikan secara statistik**
3.3 Aplikasi yang Diperluas
Untuk menunjukkan aplikasi metode yang diusulkan, kami memperluas metode kami ke klaster molekuler, di mana klaster air dipelajari untuk ruang konfigurasinya, karena eksplorasi ruang konfigurasi klaster penting dalam pemahaman mendasar tentang agregasi molekuler dan interaksi nonkovalen. Sebelumnya, ditemukan bahwa (H 2 O) 21 menampilkan fitur vibrasi yang sama dengan air cair; dengan demikian, dianggap bahwa (H 2 O) 21 adalah ukuran klaster terkecil yang membentuk setetes air secara spektroskopis. [ 51 ] Meskipun struktur klaster telah ditentukan jika seseorang ingin menentukan sifat serupa dari klaster molekuler lainnya, penentuan tersebut akan menjadi tantangan karena sulit untuk mengambil sampel konfigurasi yang cukup dalam ruang Euklides yang besar.
Dengan asumsi (H 2 O) 6 menarik sebagai tangan, kumpulan data 100 heksamer air dilatih dengan model yang diusulkan dan setiap molekul air diperlakukan sebagai manik. Gambar 6a menunjukkan tumpukan 100 heksamer air yang berada dalam garis merah. Untuk visualisasi yang lebih mudah, hanya dua dari konfigurasi (H 2 O) 6 yang dihasilkan yang masing – masing ditampilkan dalam representasi tongkat biru dan hijau. Jelas bahwa konfigurasi yang dihasilkan berbeda dari konfigurasi basis data. Karena model besar saat ini tidak dapat menghasilkan hasil yang tepat, pengoptimalan hasil yang dilatih model besar diperlukan. Jadi, menggunakan kumpulan data kecil membantu untuk mengeksplorasi ruang konfigurasi dengan menghasilkan sampel secara efisien, yang sulit untuk manipulasi manual. Strategi serupa dapat diterapkan untuk mengeksplorasi sistem permukaan-adsorbat menggunakan metode yang diusulkan juga, seperti molekul SO 2 yang diadsorpsi pada permukaan Ni(111) (Gambar 6b ).
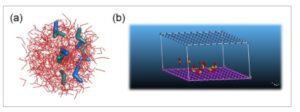
Gambar 6
Buka di penampil gambar
a) Tumpukan konfigurasi database (H 2 O) 6 (berwarna merah) dan dua konfigurasi yang dihasilkan (dalam representasi tongkat biru dan hijau). b) Representasi skema molekul SO 2 yang teradsorpsi pada permukaan Ni (111).
Terakhir, perlu dicatat pentingnya fungsi penjepit dinamis yang diusulkan dalam karya ini. Fungsi penjepit awalnya diusulkan dalam Wasserstein GAN, [ 52 ] yang bertujuan untuk meningkatkan keragaman gambar yang dihasilkan. Saat menghasilkan konfigurasi baru dalam karya ini, masalah keruntuhan mode juga ditemui dalam arti bahwa konfigurasi yang dihasilkan hampir identik, tidak peduli vektor acak awal apa yang dibaca. Untuk mengatasi masalah ini, pertama-tama kami memperkenalkan fungsi penjepit. Namun, pendekatan ini gagal untuk meningkatkan keragaman juga. Setelah kesalahan dan uji coba, kami menemukan bahwa fungsi penjepit dinamis dapat berhasil menghilangkan masalah keruntuhan mode, di mana ruang parameter dalam jaringan diskriminator secara bertahap dikurangi.
4 Kesimpulan
Dalam karya ini, kami mengusulkan metode yang efisien dengan memanfaatkan GAN yang dilatih pada kumpulan data berukuran kecil untuk menghasilkan konfigurasi klaster baru. Pendekatan yang diusulkan dan model yang dilatih dapat digunakan untuk mengeksplorasi ruang konfigurasi klaster, yang sulit diprediksi menurut intuisi kimia. Fungsi penjepit dinamis diperkenalkan untuk memecahkan masalah keruntuhan mode. Volume dan area lambung cembung disarankan untuk membantu mengidentifikasi konfigurasi klaster yang unik. Kumpulan data berukuran kecil digunakan untuk pelatihan guna mengeksplorasi kinerja metode kami. Berbagai klaster logam dipelajari untuk menghasilkan hasil tolok ukur. Ditemukan bahwa metode yang diusulkan dan model yang dilatih dapat digunakan secara efektif dengan kumpulan data kecil. Ukuran kumpulan data beberapa ratus mampu memberikan hasil yang memuaskan dalam hal menghasilkan minimum sejati yang unik, baru, dan dapat diverifikasi. Karya kami dapat merangsang studi pembelajaran mesin lebih lanjut menggunakan data berukuran kecil untuk menghindari pelatihan skala besar. Dibandingkan dengan algoritma genetik, metode yang diusulkan memiliki kinerja yang lebih baik dalam hal menghasilkan konfigurasi yang unik dan realistis. Mengingat fakta bahwa kumpulan data pelatihan dapat dipilih secara berbeda, diharapkan metode kami mungkin memiliki skenario aplikasi yang luas.



Tinggalkan Balasan